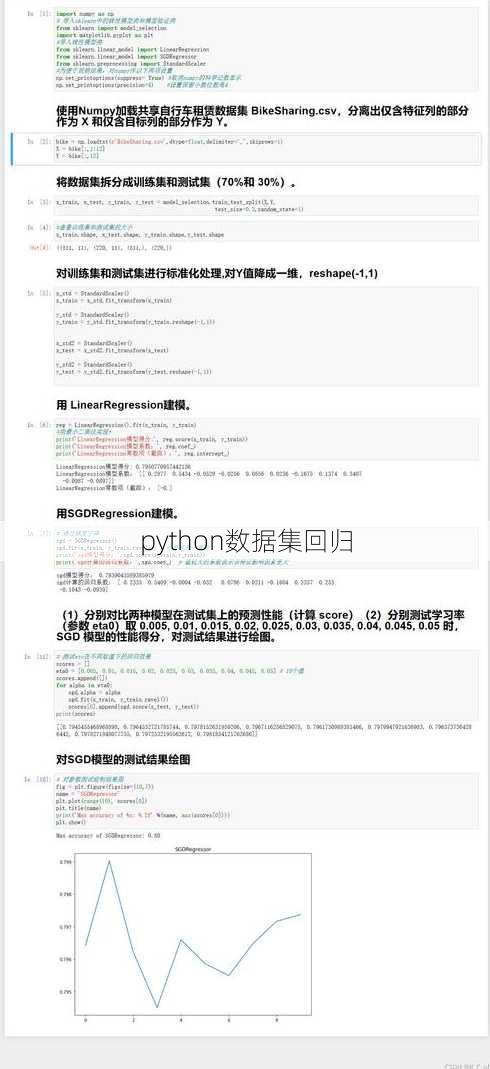
Python数据集回归分析概述
1. 什么是数据集回归分析?
数据集回归分析是统计学中的一种方法,用于探究两个或多个变量之间的关系。在Python中,回归分析通常用于预测或解释变量之间的依赖性。最常见的是线性回归,其中目标是找到一个线性方程来描述因变量与自变量之间的关系。
2. Python中常用的回归分析方法
线性回归:最基础的回归方法,假设变量之间存在线性关系。
逻辑回归:用于分类问题,将输出变量转换为概率。
多项式回归:扩展线性回归,允许非线性关系。
岭回归和Lasso回归:通过添加正则化项来减少过拟合。
3. Python中实现回归分析的常用库
scikit-learn:提供了一系列回归分析的工具,包括线性回归、逻辑回归等。
statsmodels:提供更复杂的统计模型,包括面板数据模型等。
pandas:用于数据预处理和操作。
Python数据集回归分析步骤
1. 数据准备
导入数据集。
检查数据缺失值和异常值。
对数据进行预处理,如标准化或归一化。
2. 特征选择
选择与因变量相关的自变量。
使用统计方法或模型选择算法进行特征选择。
3. 模型训练
使用选定的回归方法对数据集进行训练。
调整模型参数以优化性能。
4. 模型评估
使用交叉验证等方法评估模型性能。
评估指标包括R平方、均方误差等。
5. 模型应用
使用训练好的模型进行预测。
解释模型的输出。
常见问题及回答
Q1:什么是R平方?
A1:R平方(R²)是衡量回归模型拟合优度的一个指标,其值介于0到1之间。R²越接近1,表示模型对数据的拟合程度越好。
Q2:如何避免过拟合?
A2:过拟合是指模型在训练数据上表现良好,但在测试数据上表现不佳。以下是一些避免过拟合的方法:
使用交叉验证。
简化模型,减少参数数量。
使用正则化方法,如岭回归或Lasso回归。
Q3:如何解释回归模型的输出?
A3:回归模型的输出通常包括系数和截距。系数表示自变量对因变量的影响程度,截距表示当所有自变量为零时,因变量的预期值。通过分析系数和截距,可以了解变量之间的关系。